Create New Assisted Review Project
To create a new Assisted Review project:
-
In the navigation panel of ZyLAB One, select Assisted Review.
-
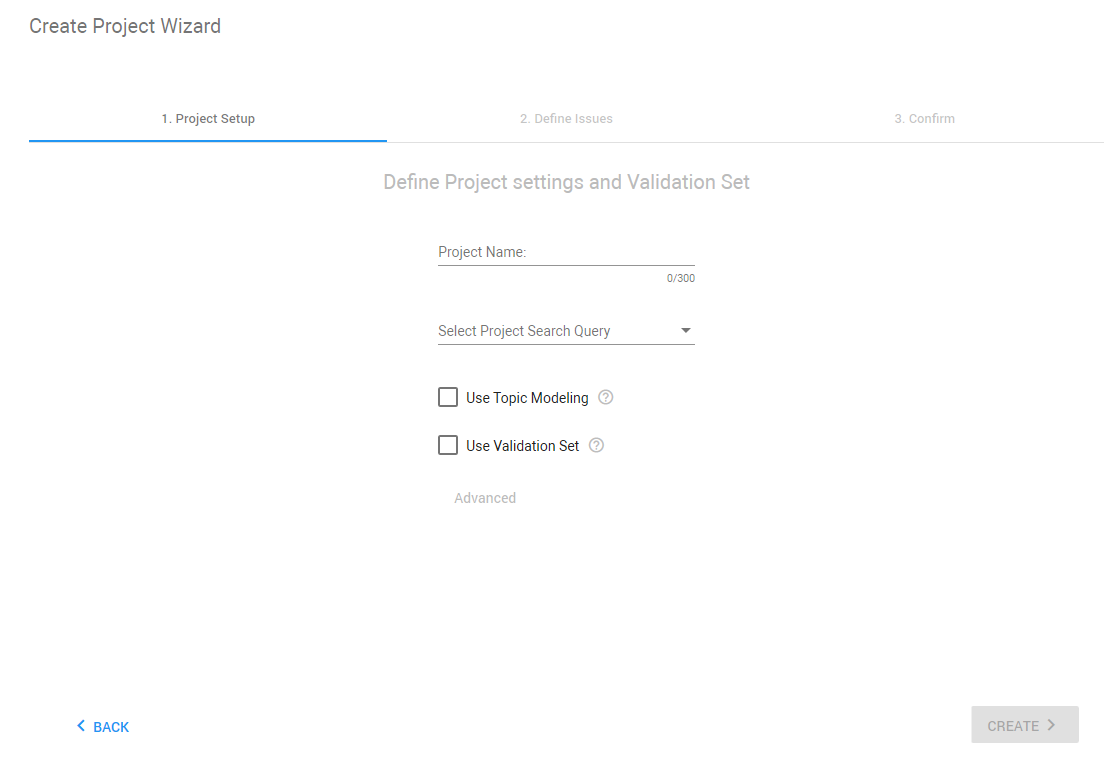
Select + Add Project. The Create Project Wizard opens.

Note: When other projects have been created already, select
 and then select + Add Project.
and then select + Add Project. -
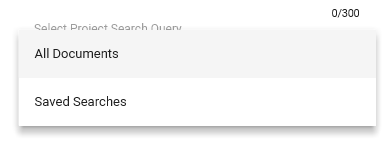
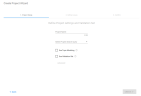
Define the Project Settings.
-
When all options have been configured, click Create.
-
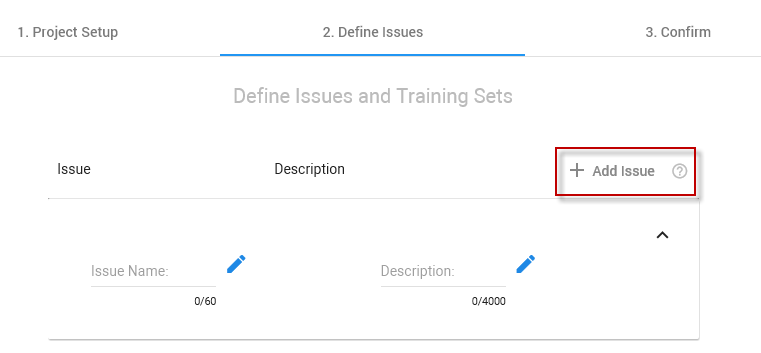
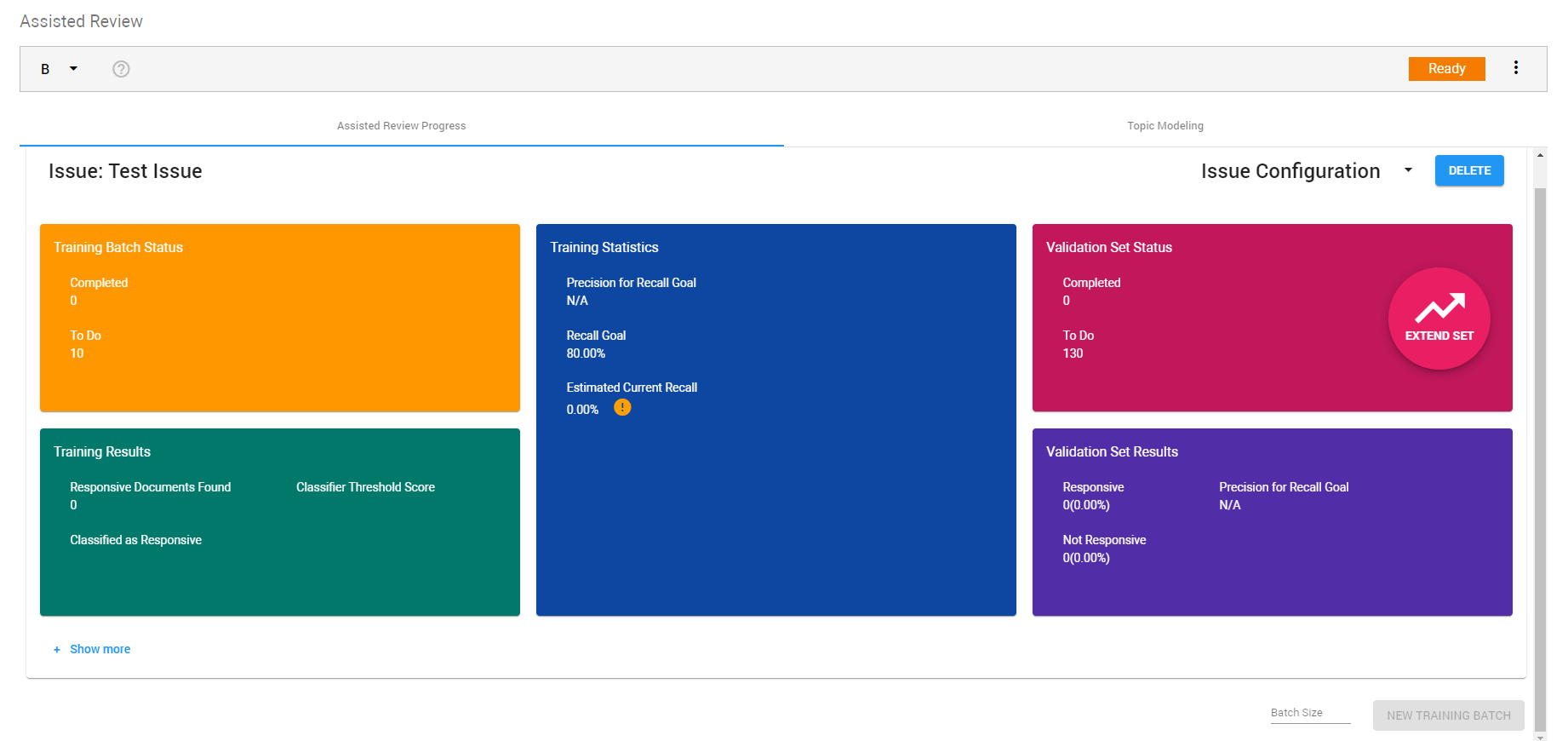
The Define Issues step opens. If needed, define one or more issues. For each issue, a training set is created.

Note: Issues may also be created at a later time. See Issue.
-
Click Next.
-
Review the project summary and click the Start Project button.
-
The classification process will be started. The progress can be viewed in the Assisted Review Progress tab.